ENCAPSULATION
As mentioned in Chapter 1, object oriented programming will seem very unnatural to a programmer with a lot of procedural programming experience. This chapter is the beginning of the definition of object oriented programming, and we will study the topic of encapsulation which is a "divide and conquer" technique. As we stated earlier, there are a lot of new terms used with object oriented programming. Don't be intimidated by the new terminology, we will study the terms one at a time in a meaningful order.
Encapsulation is the process of forming objects which we will discuss throughout this chapter. An encapsulated object is often called an abstract data type and it is what object oriented programming is all about. Without encapsulation, which involves the use of one or more classes, there is no object oriented programming. Of course there are other topics concerning object oriented programming, but this is the cornerstone.
WHY BOTHER WITH ENCAPSULATION?
We need encapsulation because we are human, and humans make errors. When we properly encapsulate some code, we actually build an impenetrable wall to protect the contained code from accidental corruption due to the silly little errors that we are all prone to make. We also tend to isolate errors to small sections of code to make them easier to find and fix. We will have a lot more to say about the benefits of encapsulation as we progress through the tutorial.
NO INFORMATION HIDING
Example program ------> OPEN.CPP
The program named OPEN.CPP is a really stupid program because it does next to nothing, but it will be the beginning point for our discussion of encapsulation, otherwise known as information hiding. Information hiding is an important part of object oriented programming and you should have a good grasp of what it is by the time we finish this chapter.
A very simple structure is defined in lines 4 through 7 which contains a single int type variable within the structure. This is sort of a silly thing to do, but it will illustrate the problem we wish to overcome in this chapter. Three variables are declared in line 11, each of which contains a single int type variable and each of the three variables are available for use anywhere within the main() function. Each variable can be assigned, incremented, read, modified, or have any number of operations performed on it. A few of the operations are illustrated in lines 14 through 22 and should be self explanatory to anyone with a little experience with the C programming language.
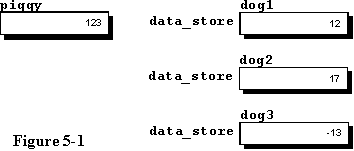 An
isolated local variable named piggy is declared and used in the
same section of code to illustrate that there is nothing magic about this
code. Figure 5-1 is a graphical representation of the data space after
execution of line 17.
An
isolated local variable named piggy is declared and used in the
same section of code to illustrate that there is nothing magic about this
code. Figure 5-1 is a graphical representation of the data space after
execution of line 17.
Study this simple program carefully because it is the basis for beginning our study of encapsulation. Be sure to compile and execute this program, then we will go on to the next example program where we will see our first example of real information hiding.
INFORMATION HIDING
Example program ------> CLAS.CPP
Examine the program named CLAS.CPP for our first example of a program with a little information hiding contained in it. This program is identical to the last one except for the way it does a few of its operations. We will take the differences one at a time and explain what is happening. Keep in mind that this is a trivial program and the safeguards built into it are not needed for such a simple program but are used here to illustrate how to use these techniques in a larger much more complicated program.
The first difference is that we have a class instead of a structure beginning in line 4 of this program. The only difference between a class and a structure is that a class begins with a private section whereas a structure begins with a public section. The keyword class is used to declare a class as illustrated here.
The class named one_datum is composed of the single variable named data_store and two functions, one named set() and the other named get_value(). A more complete definition of a class is a group of variables, and one or more functions that can operate on that data. Stay with us, we will tie this all together in a meaningful and useful way very soon.
WHAT IS A PRIVATE SECTION?
All data at the beginning of a class defaults to private. Therefore, the data at the beginning of the class cannot be accessed outside of the class, it is hidden from any outside access. Therefore, the variable named data_store which is a part of the object (an object will be defined completely later) named dog1 defined in line 24, is not available for use anywhere in the main() program. It is as if we have built a "brick wall" around the variables to protect them from accidental corruption by outside programming influences. It seems a little dumb to define a variable in the main() program that we cannot use, but that is exactly what we did.
 Figure
5-2 is a graphical representation of the class with its "brick wall"
built around the data to protect it. You will notice the small peep holes
we have opened up to allow the user to gain access to the functions get()
and get_value(). The peep holes were opened by declaring the functions
in the public section of the class.
Figure
5-2 is a graphical representation of the class with its "brick wall"
built around the data to protect it. You will notice the small peep holes
we have opened up to allow the user to gain access to the functions get()
and get_value(). The peep holes were opened by declaring the functions
in the public section of the class.
WHAT IS A PUBLIC SECTION?
A new keyword, public, is introduced in line 7 which states that anything following this keyword can be accessed from outside of this class. Because the two functions are declared following the keyword public, they are both public and available for use by any calling program that is within the scope of this object. This essentially opens two small peepholes in the solid wall of protection that we built around the class. You should keep in mind that the private variable is not available to the calling program. Thus, we can only use the variable by calling one of the two functions defined within the public part of the class. These are called member functions because they are members of the class.
Since we have declared two functions, we need to define them by saying what each function will actually do. This is done in lines 12 through 20 where they are each defined in the normal way, except that the class name is prepended onto the function name and separated from it by a double colon. These two function definitions are called the implementation of the functions. The class name is required because we can use the same function name in other classes and the compiler must know with which class to associate each function implementation.
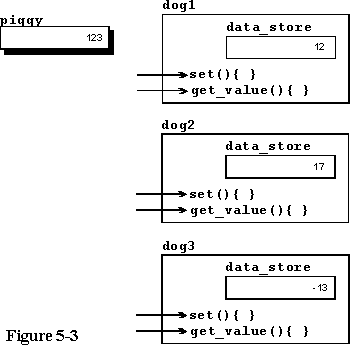 One
of the key points to be made here is that the private data contained within
the class is available within the implementation of the member functions
of the class for modification or reading in the normal manner. You can
do anything with the private data within the function implementations which
are a part of that class, but the private data of other classes is hidden
and not available within the member functions of this class. This is the
reason we must prepend the class name to the function names of this class
when defining them. Figure 5-3 depicts the data space following execution
of line 30.
One
of the key points to be made here is that the private data contained within
the class is available within the implementation of the member functions
of the class for modification or reading in the normal manner. You can
do anything with the private data within the function implementations which
are a part of that class, but the private data of other classes is hidden
and not available within the member functions of this class. This is the
reason we must prepend the class name to the function names of this class
when defining them. Figure 5-3 depicts the data space following execution
of line 30.
It would be well to mention at this point that it is legal to declare variables and functions in the private part, and additional variables and functions in the public part also. In most practical situations, variables are declared in only the private part and functions are declared in only the public part of a class definition. Occasionally, variables or functions are declared in the other part. This sometimes leads to a very practical solution to a particular problem, but in general, the entities are used only in the places mentioned.
In C++ we have four scopes of variables, global, local, file, and class. Global variables are available anywhere in the defining file and in other files. Local variables are localized to a single function. File variables, those that are defined outside of any function, are available anywhere in a file following their definition. A variable with class scope is available anywhere within the scope of a class, including the implementation code, and nowhere else. The variable named data_store has a class scope.
You must be very confused by this point since we have given a lot of rules but few reasons for doing all of this. Stay with us and you will soon see that there are very practical reasons for doing all of this.
MORE NEW TERMINOLOGY
As with most new technologies, developers seem to delight in making up new names for all aspects of their new pet. Object oriented programming is no different, so we must learn new names for some of our old familiar friends if we are going to learn how to effectively use it. To help you learn this new programming terminology, we will list a few of them here and begin using them in the text to get you used to seeing and using them. You will not understand them all yet, but we need to introduce them early.
With all the new terminology, we will continue our study of the program named CLAS.CPP and show you how to use the class. We can now say that we have a class composed of one variable and two methods. The methods operate on the variable contained in the class when they receive messages to do so. In this tutorial we will use the terms object and variable interchangeably because both names are very descriptive of what the object really is.
This is a small point but it could be easily overlooked. Lines 8 and 9 of this program are actually the prototypes for the two methods, and is our first example of the use of a prototype within a class. This is the reason we spent extra time studying prototypes in the last chapter. You will notice line 8 which says that the method named set() requires one parameter of type int and returns nothing, hence the return type is void. The method named get_value() however, according to line 9, has no input parameters but returns an int type value to the caller.
SENDING A MESSAGE
Following all of the definitions in lines 1 through 20, we finally come to the program where we actually use the class. In line 24 we define three objects of the class one_datum and name the objects dog1, dog2, and dog3. You will notice that the keyword class is not included in this line because it is not needed. Each object contains a single data point which we can set through use of the method set() or read through use of the method get_value(), but we cannot directly set or read the value of the data point because it is hidden within the "block wall" around the class. In line 27, we send a message to the object named dog1 instructing it to set its internal value to 12, and even though this looks like a function call, it is properly called sending a message to a method. Remember that the object named dog1 has a method associated with it called set() that sets its internal value to the actual parameter included within the message. You will notice that the form is very much like the means of accessing the elements of a structure. You mention the name of the object with a dot connecting it to the name of the method. In a similar manner, we send a message to each of the other two objects, dog2 and dog3, to set their values to those indicated.
Lines 32 and 33 have been commented out because the operations are illegal. The variable named data_store is private and therefore not available to the code outside of the object itself. It should be obvious, but it will be pointed out that the data contained within the object named dog1 is not available within the methods of dog2 or dog3 because they are different objects. These rules are all devised to help you develop better code more quickly and you will soon see how they help.
The other method defined for each object is used in lines 35 through 37 to illustrate how it can be used. In each case, another message is sent to each object and the returned result is output to the monitor via the stream library.
USING A NORMAL VARIABLE
There is another variable named piggy declared and used throughout this example program that illustrates that a normal variable can be intermixed with the objects and used in the normal manner. The use of this variable should pose no problem to you, so after you understand the program, be sure to compile and execute it. It would be a good exercise for you to remove the comments from lines 32 and 33 to see what kind of error message your compiler issues.
This program illustrates information hiding but it will not be clear to you that it really does anything worthwhile until we study the next two programs. Be sure to compile and execute this program, then remove the comments from lines 32 and 33 as suggested, to see the error messages issued.
A PROGRAM WITH PROBLEMS
Example program ------> OPENPOLE.CPP
Examine the program named OPENPOLE.CPP for an example of a program with a few serious problems that will be overcome in the next example program by using the principles of encapsulation.
We have two structures declared, one being a rectangle and the other a pole. The data fields should be self explanatory with the exception of the depth of the flagpole which is the depth it is buried in the ground, the overall length of the pole is therefore the sum of the length and the depth.
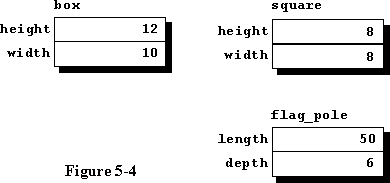 Figure
5-4 depicts the data space for this program after execution of line 34.
Based on your experience with ANSI-C, you should have no problem understanding
exactly what this program is doing, but you may be a bit confused at the
meaning of the result found in line 40 where we multiply the height
of the square with the width of the box. This
is perfectly legal to do in ANSI-C or C++, but the result has no earthly
meaning because the data are for two different entities. Likewise, the
result calculated in line 42 is even sillier because the product of the
height of the square and the depth of the flagpole
has absolutely no meaning in any physical system we can think up. The
error is obvious in a program as simple as this, but in a large production
program it is very easy for such problems to be inadvertently introduced
into the code and the errors can be very difficult to find.
Figure
5-4 depicts the data space for this program after execution of line 34.
Based on your experience with ANSI-C, you should have no problem understanding
exactly what this program is doing, but you may be a bit confused at the
meaning of the result found in line 40 where we multiply the height
of the square with the width of the box. This
is perfectly legal to do in ANSI-C or C++, but the result has no earthly
meaning because the data are for two different entities. Likewise, the
result calculated in line 42 is even sillier because the product of the
height of the square and the depth of the flagpole
has absolutely no meaning in any physical system we can think up. The
error is obvious in a program as simple as this, but in a large production
program it is very easy for such problems to be inadvertently introduced
into the code and the errors can be very difficult to find.
Wouldn't it be neat if we had a way to prevent such stupid things from happening in a large production program. If we had a good program that defined all of the things we can do with a square and another program that defined everything we could do with a pole, and if the data could be kept mutually exclusive, we could prevent these silly things from happening. If these entities must interact, they cannot be put into separate programs, but they can be put into separate classes to achieve the desired goal.
It should come as no real surprise to you that the next program will do just those things for us and do it in a very elegant way. Before proceeding on to the next example program, you should compile and execute this one even though it displays some silly results.
OBJECTS PROTECT DATA
Example program ------> CLASPOLE.CPP
Examine the program named CLASPOLE.CPP as an example of data protection in a very simple program.
In this program, the rectangle is changed to a class with the same two variables which are now private, and two methods which can manipulate the private data. One method is used to initialize the values of the objects created and the other method returns the area of the object. The two methods are defined in lines 13 through 22 in the manner described earlier in this chapter. The pole is left as a structure to illustrate that the two can be used together and that C++ is truly an extension of ANSI-C.
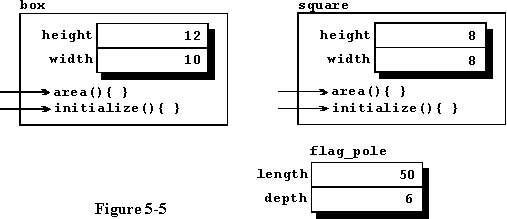
In line 35 we define two objects, once again named box and square, but this time we cannot assign values directly to their individual components because they are private elements of the class. Figure 5-5 is a graphical illustration of the two objects available for use within the calling program. Lines 38 through 40 are commented out for that reason and the messages are sent to the objects in lines 42 and 43 to tell them to initialize themselves to the values input as parameters. The flag_pole is initialized in the same manner as in the previous program. Using the class in this way prevents us from making the silly calculations we did in the last program, because we can only calculate the area of an object by using the data stored within that object. The compiler is now being used to prevent the erroneous calculations. The end result is that the stupid calculations we did in the last program are not possible in this program, so lines 52 through 55 have been commented out. Once again, it is difficult to see the utility of this in such a simple program. In a large program, using the compiler to enforce the rules can pay off in a big way.
Even though the square and the box are both objects of class rectangle, their private data is hidden from each other such that neither can purposefully or accidentally change the other's data.
This is the abstract data type mentioned earlier in this chapter, a model with a set of private variables for data storage and a set of operations that can be performed on that stored data. The only operations that can be performed on the data are those defined by the methods, which prevents many kinds of erroneous or silly operations. Encapsulation and data hiding bind the data and procedures, or methods, tightly together and limit the scope and visibility of each. Once again, we have the divide and conquer technique in which an object is separated from the rest of the code and carefully developed in complete isolation from it. Only then is it integrated into the rest of the code with a few very simple interfaces.
Someone did a study several years ago in which they determined that programmers accidentally corrupted data much more often than they accidentally corrupted code. So it was determined that if the data could be protected from accidental corruption, the quality of the software could be improved. This is where the idea of information hiding originated and it has proven itself to be very valuable over the years.
HAVE YOU EVER USED THIS TECHNIQUE BEFORE?
A good example of the use of this technique is in the file commands you have been using with ANSI-C. The data in the file is only available through the predefined functions provided by your compiler writer. You have no direct access to the actual data because it is impossible for you to address the actual data stored on the disk. The data is therefore private data, as far as you are concerned, but the available functions are very much like methods in C++.
There are two aspects of this technique that really count when you are developing software. First, you can get all of the data you really need from the file system because the interface is complete, but secondly, you cannot get any data that you do not need. You are prevented from getting into the file handling system and accidentally corrupting some data stored within it. You are also prevented from using the wrong data because the functions available demand a serial access to the data. I should mention that this is a very weak example because it is very easy for a knowlegeable C programmer to break the encapsulation provided by the file system.
Another example of weak encapsulation is the monitor and keyboard handling routines. You are prevented from getting into the workings of them and corrupting them accidentally, but you are provided with all of the data interfaces that you really need to effectively use them.
Suppose you are developing a program to analyze some characteristics of flagpoles. You would not wish to accidentally use some data referring to where the flagpole program was stored on your hard disk as the height of the flagpole, nor would you wish to use the cursor position as the flagpole thickness or color. All code for the flagpole is developed alone, and only when it is finished, is it available for external use. When using it, you have a very limited number of operations which you can do with the class. The fact that the data is hidden from you protects you from accidentally doing such a thing when you are working at midnight to try to meet a schedule. Once again, this is referred to as information hiding and is one of the primary advantages of object oriented programming over procedural techniques.
Based on the discussion given above you can see that object oriented programming is not really new, since it has been used in a small measure for as long as computers have been popular. The newest development, however, is in allowing the programmer to partition his programs in such a way that he too can practice information hiding to reduce the debugging time and improve the quality of his software.
WHAT DOES THIS COST?
It should be clear that this technique will cost you something in efficiency because every access to the elements of the object will require the time and inefficiency of a call to a function, or perhaps I should be more proper and refer to it as a method. The time saved in building a large program, however, could easily be saved in debug time when it comes time to iron out the last few bugs. This is because a program made up of objects that closely match the application are much easier to understand than a program that does not.
This is obviously such a small program that it is silly to try to see any gain with this technique. In a real project however, it could be a great savings if one person developed all of the details of the rectangle, programmed it, and made it available to you to simply use. This is exactly what has been done for you if you consider the video monitor an object. There is a complete set of preprogrammed and debugged routines you can use to make the monitor do anything you wish it to do, all you have to do is study the interface to the routines and use them, expecting them to work. You have no need to study the implementation, nor are you required to understand it, provided that it works. As we mentioned earlier, it is impossible for you to multiply the size of your monitor screen by the depth of the flag pole because that information is not available to you to use in a corruptible way.
After you understand some of the advantages of this style of programming, be sure to compile and execute this program.
CONSTRUCTORS AND DESTRUCTORS
Example program ------> CONSPOLE.CPP
The file named CONSPOLE.CPP introduces constructors and destructors and should be examined at this time.
This example program is identical to the last example except that a constructor has been added as well as a destructor. The constructor always has the same name as the class itself and is declared in line 9, then defined in lines 15 through 19. The constructor is called automatically by the C++ system when the object is declared and prevents the use of an uninitialized variable. When the object named box is defined in line 48, the constructor is called automatically by the system. The constructor sets the values of height and width each to 6 in the object named box. This is printed out for reference in lines 51 and 52. Likewise, when the square is defined in line 48, the values of the height and the width of the square are each initialized to 6 when the constructor is called automatically.
A constructor is defined as having the same name as the class itself. In this case both are named rectangle. The constructor cannot have a return type associated with it because of the definition of C++. It actually has a predefined return type, a pointer to the object itself, but we will not be concerned about this until much later in this tutorial. Even though both objects are assigned values by the constructor, they are initialized in lines 60 and 61 to new values and processing continues. Since we have a constructor that does the initialization, we should probably rename the method named initialize() something else but it illustrates the concept involved here.
The destructor is very similar to the constructor except that it is called automatically when each of the objects goes out of scope. You will recall that automatic variables have a limited lifetime because they cease to exist when the enclosing block in which they were declared is exited. When an object is about to be automatically deallocated, its destructor, if one exists, is called automatically. A destructor is characterized as having the same name as the class but with a tilde prepended to the class name. A destructor has no return type.
A destructor is declared in line 12 and defined in lines 32 through 36. In this case the destructor only assigns zeros to the variables prior to their being deallocated, so nothing is really accomplished. The destructor is only included for illustration of how it is used. If some blocks of memory were dynamically allocated within an object, the destructor should contains code to deallocate them prior to losing the pointers to them. This would return their memory to the free store for further use later in the program.
It is interesting to note that if a constructor is used for an object that is declared prior to the main() program, a global variable, the constructor will actually be executed prior to the execution of the main() program. In like manner, if a destructor is defined for such a variable, it will execute following the completion of execution of the main() program. This will not adversely affect your programs, but it is interesting to make note of.
OBJECT PACKAGING
Example program ------> BOXES1.CPP
Examine the file named BOXES1.CPP for an example of how not to package an object for universal use. This packaging is actually fine for a very small program, but is meant to illustrate to you how to split your program up into smaller, more manageable files when you are developing a large program or when you are part of a team developing a large system. The next three example files in this chapter will illustrate the proper method of packaging a class.
This program is very similar to the last one with the pole structure dropped and the class named box. The class is declared in lines 4 through 13, the implementation of the class is given in lines 16 through 35, and the use of the class is given in lines 38 through 52. With the explanation we gave about the last example program, the diligent student should have no problem understanding this program in detail.
INLINE IMPLEMENTATION
The method in line 11 contains the implementation for the method as a part of the declaration because it is very simple, and because it introduces another new topic which you will use often in C++ programming. When the implementation is included in the declaration, it will be assembled inline wherever this function is called leading to much faster code. This is because there is no function call overhead when making a call to the method. In some cases this will lead to code that is both smaller and faster. This is yet another illustration of the efficiency built into the C++ programming language. Inline code implementation in C++ accomplishes the same efficiency that the macro accomplishes in C, and is the constuct of choice for small functions.
Compile and execute this program in preparation for our study of the next three examples which are a repeat of this program in a slightly different form.
THE CLASS HEADER FILE
Example program ------> BOX.H
If you examine BOX.H carefully, you will see that it is only the class definition. No details are given of how the various methods are implemented except of course for the inline method named get_area(). This gives the complete definition of how to use the class with no implementation details. You would be advised to keep a hardcopy of this file available as we study the next two files. You will notice that it contains lines 4 through 13 of the previous example program named BOXES1.CPP. This is called the class header file and cannot be compiled or executed.
THE CLASS IMPLEMENTATION FILE
Example program ------> BOX.CPP
Examine the file named BOX.CPP for the implementation of the methods declared in the class header file. Notice that the class header file is included into this file in line 2 which contains the prototypes for its methods and the definitions of the variables to be manipulated. The code from lines 16 through 35 of BOXES1.CPP is contained in this file which is the implementation of the methods declared in the class named box.
This file can be compiled but it cannot be executed because there is no main entry point which is required for all ANSI-C or C++ programs. When it is compiled, the object code will be stored in the current directory and available for use by other programs. It should be noted here that the result of compilation is usually referred to as an object file because it contains object code. This use of the word object has nothing to do with the word object as used in object oriented programming. It is simply a matter of overloading the use of the word. The practice of referring to the compiled result as an object file began long before the technique of object oriented programming was ever considered.
The separation of the definition and the implementation is a major step forward in software engineering. The definition file is all the user needs in order to use this class effectively in a program. He needs no knowledge of the actual implementation of the methods. If he had the implementation available, he may study the code and find a trick he could use to make the overall program slightly more efficient, but this would lead to nonportable software and possible bugs later if the implementor changed the implementation without changing the interface. The purpose of object oriented programming is to hide the implementation in such a way that the implementation can not affect anything outside of its own small and well defined boundary or interface.
You should compile this implementation file now and we will use the result with the next example program.
USING THE BOX OBJECT
Example program ------> BOXES2.CPP
Examine the file named BOXES2.CPP and you will find that the class we defined previously is used within this file. In fact, these last three programs taken together are identical to the program named BOXES1.CPP studied earlier.
The BOX.H file is included here, in line 3, since the definition of the box class is needed to declare three objects and use their methods. You should have no trouble seeing that this is a repeat of the previous program and will execute in exactly the same way. There is a big difference in BOXES1.CPP and BOXES2.CPP as we will see shortly.
A very important distinction must be made at this point. We are not merely calling functions and changing the terminology a little to say we are sending messages. There is an inherent difference in the two operations. Since the data for each object is tightly bound up within the object, there is no way to get to the data except through the methods and we send a message to the object telling it to perform some operation based on its internally stored data. However, whenever we call a function, we take along the data for it to work with as parameters since it doesn't contain its own data. Admittedly, the difference is slight, but you will see the new terminology used in the literature, and you need to realize that there is a slight difference.
Be sure to compile and execute this program, but when you come to the link step, you will be required to link this program along with the result of the compilation when you compiled the class named box. The file is probably named BOX.OBJ that must be linked with this file. You may need to consult the documentation for your C++ compiler to learn how to do this.
Depending on your compiler, this is your first opportunity to use either a project file, or the "make" facility included with your compiler. Regardless of which C++ compiler you are using, it would pay you to stop and learn how to use the multifile technique provided with your compiler because you will need to use it several times before the end of this tutorial. The nature of C++ tends to drive the programmer to use many files for a given programming project and you should develop the habit early.
INFORMATION HIDING
The three example programs we have just studied illustrate a method of information hiding that can have a significant impact on the quality of software developed for a large project. Since the only information the user of the class really needs is the class header, that is all he needs to be given. The details of implementation can be kept hidden from him to prevent him from studying the details and possibly using a quirk of programming to write some rather obtuse code. Since he doesn't know exactly what the implementor did, he must follow only the definition given in the header file. This can have a significant impact on a large project. As mentioned earlier, accidental corruption of data is prevented also.
Another reason for hiding the implementation is economic. The company that supplied you with your C++ compiler gave you many library functions but did not supply the source code to the library functions, only the interface to each function. You know how to use the file access functions but you do not have the details of implementation, nor do you need them. Likewise a class library industry can develop which supplies users with libraries of high quality, completely developed and tested classes, for a licensing fee of course. Since the user only needs the interface defined, he can be supplied with the interface and the object (compiled) code for the class and can use it in any way he desires. The suppliers source code is protected from accidental or intentional compromise and he can maintain complete control over it.
It is very important that you understand the principles covered in this chapter before proceeding on to the next chapter. If you feel you are a little weak in any of the areas covered here, you should go over them again before proceeding on. A point that should be made here that may be obvious to you, is that it requires a considerable amount of forethought to effectively use classes.
ABSTRACT DATA TYPES
We mentioned the abstract data type at the beginning of this chapter and again briefly midway through, and it is time to describe it a little more completely. An abstract data type is a group of data, each of which can store a range of values, and a set of methods or functions that can operate on that data. Since the data are protected from any outside influence, it is protected and said to be encapsulated. Also, since the data is somehow related, it is a very coherent group of data that may be highly interactive with each other, but with little interaction outside the scope of its class.
The methods, on the other hand, are coupled to the outside world through the interface, but there are a limited number of contacts with the outside world and therefore a weak coupling with the outside. The object is therefore said to be loosely coupled to the outside world. Because of the tight coherency and the loose coupling, ease of maintenance of the software is greatly enhanced. The ease of maintenance may be the greatest benefit of object oriented programming.
It may bother you that even though the programmer may not use the private variables directly outside of the class, they are in plain sight and he can see what they are and can probably make a good guess at exactly how the class is implemented. The variables could have been hidden completely out of sight in another file, but because the designers of C++ wished to make the execution of the completed application as efficient as possible, the variables were left in the class definition where they can be seen but not used.
FRIEND FUNCTIONS
A function outside of a class can be defined to be a friend function by the class which gives the friend free access to the private members of the class. This in effect, opens a small hole in the protective shield of the class, so it should be used very carefully and sparingly. There are cases where it helps to make a program much more understandable and allows controlled access to the data. Friend functions will be illustrated in some of the example programs later in this tutorial. It is mentioned here for completeness of this section. A single isolated function can be declared as a friend, as well as members of other classes, and even entire classes can be given friend status if needed in a program. Neither a constructor nor a destructor can be a friend function.
THE struct IN C++
The struct is still useable in C++ and operates just like it does in ANSI-C with one addition. You can include methods in a structure that operate on data in the same manner as in a class, but methods and data are automatically defaulted to be public at the beginning of a structure. Of course you can make any of the data or methods private by defining a private section within the structure. The structure should be used only for constructs that are truly structures. If you are building even the simplest objects, you are advised to use classes to define them.
A VERY PRACTICAL CLASS
The examples of encapsulation used in this chapter have all been extremely simple in order to illustrate the mechanics of encapsulation. Since it would be expedient to study a larger example, the date class is given for your instruction. The date class is a complete nontrivial class which can be used in any program to get the current date and print it as an ASCII string in any of four predefined formats. It can also be used to store any desired date and format it for display.
Example program ------> DATE.H
Examine the file named DATE.H which is the header file for the date class. This file is so well commented that we don't have much else to say about it. If you understand the principles covered in this chapter you should have no problem understanding this class. One thing that is new to you is the reserved word protected which is used in line 13. We will define this word in a couple of chapters. Until then, pretend that it means the same thing as private and you will be close enough for this present example. The code in lines 8 and 9 along with line 58 will be explained shortly. For the present time, simply pretend those lines of code are not there. Also the keyword static as used in lines 18 and 19 will be explained later. These new constructs are added because we plan to use this class later when we study inheritance.
You should spend the time necessary to completely understand this class header, with the exception of the new things added, before going on to the implementation for this class.
Example program ------> DATE.CPP
The file named DATE.CPP is the implementation for the date class and once again, there is nothing unusual or difficult about this code. It uses very simple logic to store and format the date in a usable manner. You should study this code until you understand it completely before going on to the next example which will use the date class in a main program.
The constructor implementation in lines 14 through 25 use DOS system calls to get the current date. Unless you are using 16 bit DOS, these calls will not be compiled or executed properly because they are not portable. You can modify this code so it uses calls to your system or simply assign the member variables some default values. The purpose of this code is to illustrate the use of encapsulation and constructors, not how to read the real time clock and calendar on your particular computer.
Example program ------> USEDATE.CPP
The very simple program named USEDATE.CPP is a main program that uses the date class to list the current date and another date on the monitor. Once again, you should have no problem understanding this program so nothing more will be said about it.
You should spend the time necessary to understand these three files because they are the starting point for a practical track in the next few chapters. This class will be used in conjunction with others to illustrate single and multiple inheritance. Even though you do not understand all of the details of these files, spend enough time that you are comfortable with the structure and the major points of them.
We will continue our discussion of encapsulation in the next chapter.
PROGRAMMING EXERCISES
John Paul Doe
J. P. Doe
Doe, John Paul
and any other formats you desire.
Return to the Table of Contents